1. Getting started
Getting Started
Unix
Things covered here:
- Accessing our Unix-like environment
- Some general rules
- Running commands and general syntax
- File-system structure and how to navigate
Accessing our command-line environment
Before we get started, we need a terminal to work in. You can either work on your own computer if you already have access to a Unix-like command-line environment (which you can get help with here if needed), or you can work in a “Binder” that’s been created for these 5 Introduction to Unix lessons. Binder is an incredible project with incredible people behind hit. I’m still pretty new to it, but the general idea is it makes it easier to setup and share specific working environments in support of open science. What this means for us here is that we can just click this little badge – ![]() – and it’ll open the proper Unix environment in our web-browser with all our needed example files ready to rock… how awesome is that?!? So yeah, if you want to work in the binder, click it already!
– and it’ll open the proper Unix environment in our web-browser with all our needed example files ready to rock… how awesome is that?!? So yeah, if you want to work in the binder, click it already!
When that page finishes loading (it may take a minute), you will see a screen like this (minus the blue arrows):
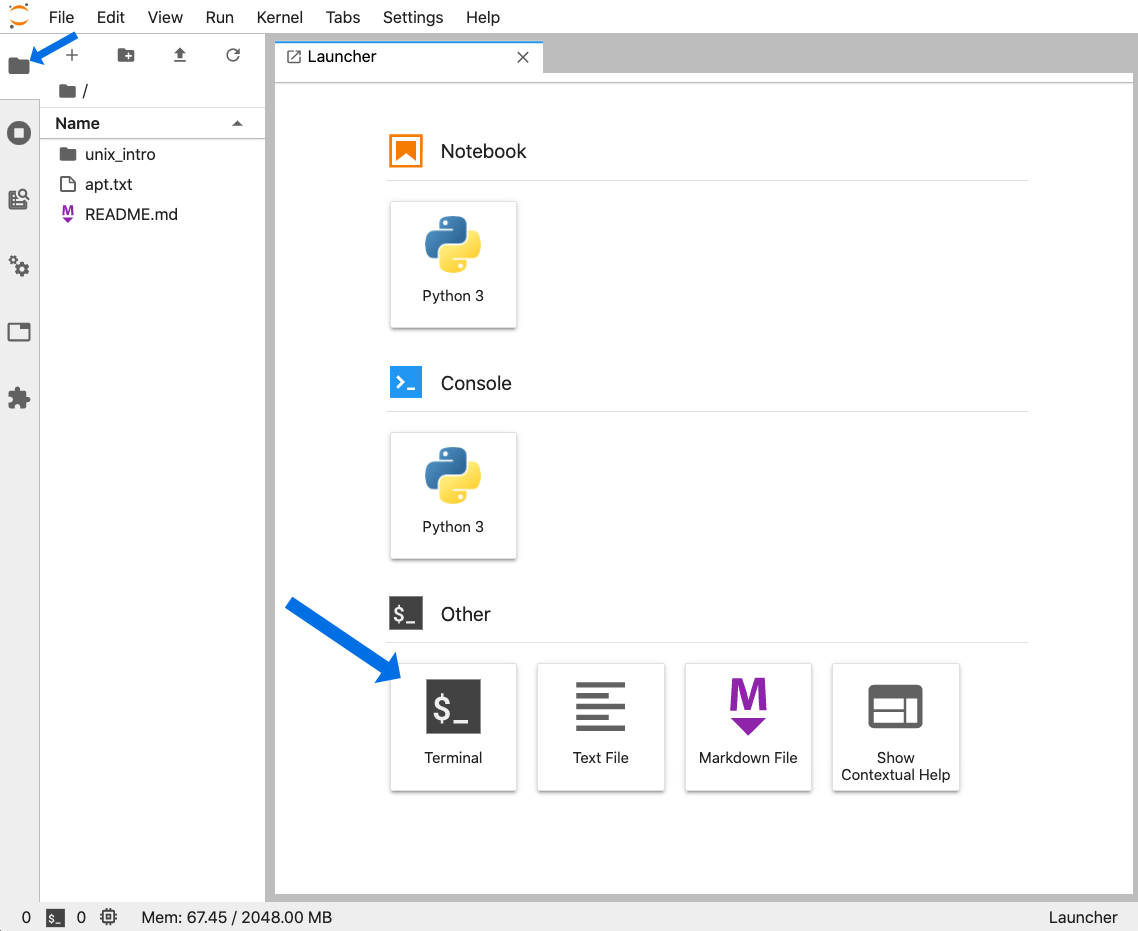
Now click the folder icon at the top-left (that the smaller blue arrow points to above) and then click the “Terminal” icon at the bottom, and we’ll be in our appropriate command-line environment:
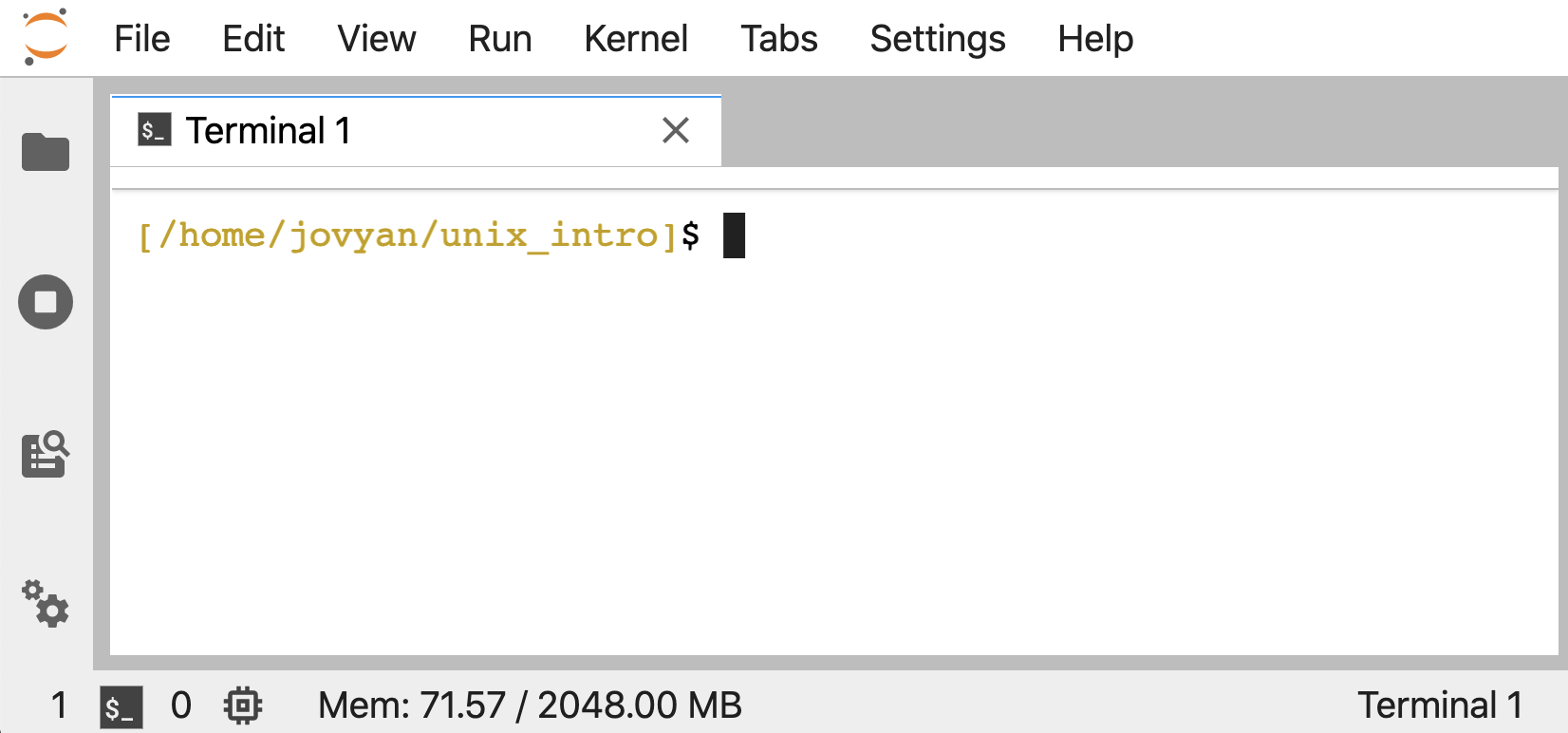
This is our “command line”, where we will be typing all of our commands 🙂
Note: If you want to get a Unix environment of your own going on your computer, you can see this page for some help, and can then follow this page working on your own computer.
If you are not using the binder environment, but want to follow along with this page, then for right now, and only for right now, I would like you to blindly copy and paste the following commands into your terminal window. This is so that we are working in the same place with the same files.
cd ~
curl -L -o unix_intro.tar.gz https://ndownloader.figshare.com/files/15573746
tar -xzvf unix_intro.tar.gz && rm unix_intro.tar.gz
cd unix_intro
Don’t forget to press enter to execute the last command (usually that doesn’t copy over). If your system does not have curl installed, and you get an error message from the above, then it’s probably best to work in the binder environment for now while getting used to things 🙂
A few foundational rules
-
Spaces are special! The command line uses spaces to know how to properly break things apart. This is why it’s not ideal to have filenames that contain spaces, but rather it’s better to use dashes (
-) or underscores (_) – e.g., “draft-v3.txt” is preferred over “draft v3.txt”.
-
The general syntax working at the command line goes like this:
command argument.
-
Arguments (which can also be referred to as “flags” or “options” or “parameters”) can be optional or required based on the command being used.
Now, let's get started!
Running commands
NOTE: It’s okay to copy and paste things throughout this intro if you’d like. There will be lots of time forever moving forward to worry about each individual character being perfect. Right now is just about the concepts 🙂
date is a command that prints out the date and time. This particular command doesn’t require any arguments:
date
When we run date with no arguments, it uses some default settings, like assuming we want to know the time in our computer’s local time zone. But we can provide optional arguments to date.
Optional arguments most often require putting a dash in front of them in order for the program to interpret them properly.
Here, we are adding the -u argument to tell it to report UTC time instead of the local time – which will be the same if the computer we’re using happens to be set to UTC time, of course 🙂:
date -u
Note that if we try to run it without the dash, we get an error:
date u
Also note that if we try to enter this without the “space” separating date and the optional argument -u, the computer won’t know how to break apart the command and we get a different error:
date-u
Notice that the first error comes from the program
date, so the program we wanted is responding to us, but it doesn’t know what to do with the letteruwe gave it. The second error comes frombash, the language we are working in, telling us it can’t find a command (or program) called “date-u” – which it’s looking for because we didn’t tell it how ot properly break things apart (because we removed the needed space).
Unlike date, most commands require arguments and won’t work without them. head is a command that prints the first lines of a file, so it requires us to provide the file we want it to act on. Here is printout out the first lines of a file called “example.txt”:
head example.txt
Here “example.txt” is the required argument, and in this case it is also what’s known as a positional argument (we’ll see examples of what’s not a positional argument in a second).
Whether things need to be provided as positional arguments or not depends on how the command or program we are using was written. Sometimes we need to specify the input file by putting something in front of it (e.g., some commands will use the -i flag, but it’s often other things as well).
There are also optional arguments for the head command. The default for head is to print the first 10 lines of a file. We can change that by specifying the -n flag, followed by how many lines we want:
head -n 5 example.txt
How would we know we needed the -n flag for that? There are a few ways to find out. Many standard Unix commands and other programs will have built-in help menus that we can access by providing -h or --help as the only argument:
head -h
head --help
That spit out a lot of information (and head is a relatively simple command compared to many others), but somewhere in there we can see “-n, –lines…” (we could have used --lines 5 instead of -n 5 to get the same result), but even that can be confusing if we’re not use to how this information is presented.
I usually try a built-in help menu first, because it’s usually immediately accessible and might help. But if it’s not working out, I very quickly go to our good friend google, which will often have a more easily understood answer for me somehwere.
What options are available for a certain command, and how to specify them, are parts of this process that are not about memorization at all. We might remember a few flags or specific options if we happen to use them a lot, but searching for options and details when needed is definitely the norm!
What we've done so far already really is the framework for how almost all things work at the command line! Multiple commands can be strung together, and some commands can have many options, inputs, and outputs and can grow to be quite long, but this is the general framework that underlies it all.Becoming familiar with these baseline rules is important, memorizing particular commands and options is not!
The Unix file-system structure
Computers store file locations in a hierarchical structure. We are typically already used to navigating through this stucture by clicking on various folders (also known as directories) in a Windows Explorer window or a Mac Finder window. Just like we need to select the appropriate files in the appropriate locations there (in a Graphical User-Interface, or GUI), we need to do the same when working at a command-line interface. What this means in practice is that each file and directory has its own “address”, and that address is called its “path”.
Additionally, there are two special locations in all Unix-based systems, so 2 more terms we should become familiar with: the “root” location and the current user’s “home” location. “Root” is where the address system of the computer starts; “home” is where the current user’s location starts.
Here is an image of an example file-system structure. Let’s take a peek at it. First imagining just “clicking” through folders (directories) in a GUI in order to reach the file we want, “processing_notes.txt”. Then we’ll talk about it in terms of the “path” we could use to get to the same file at the command line.
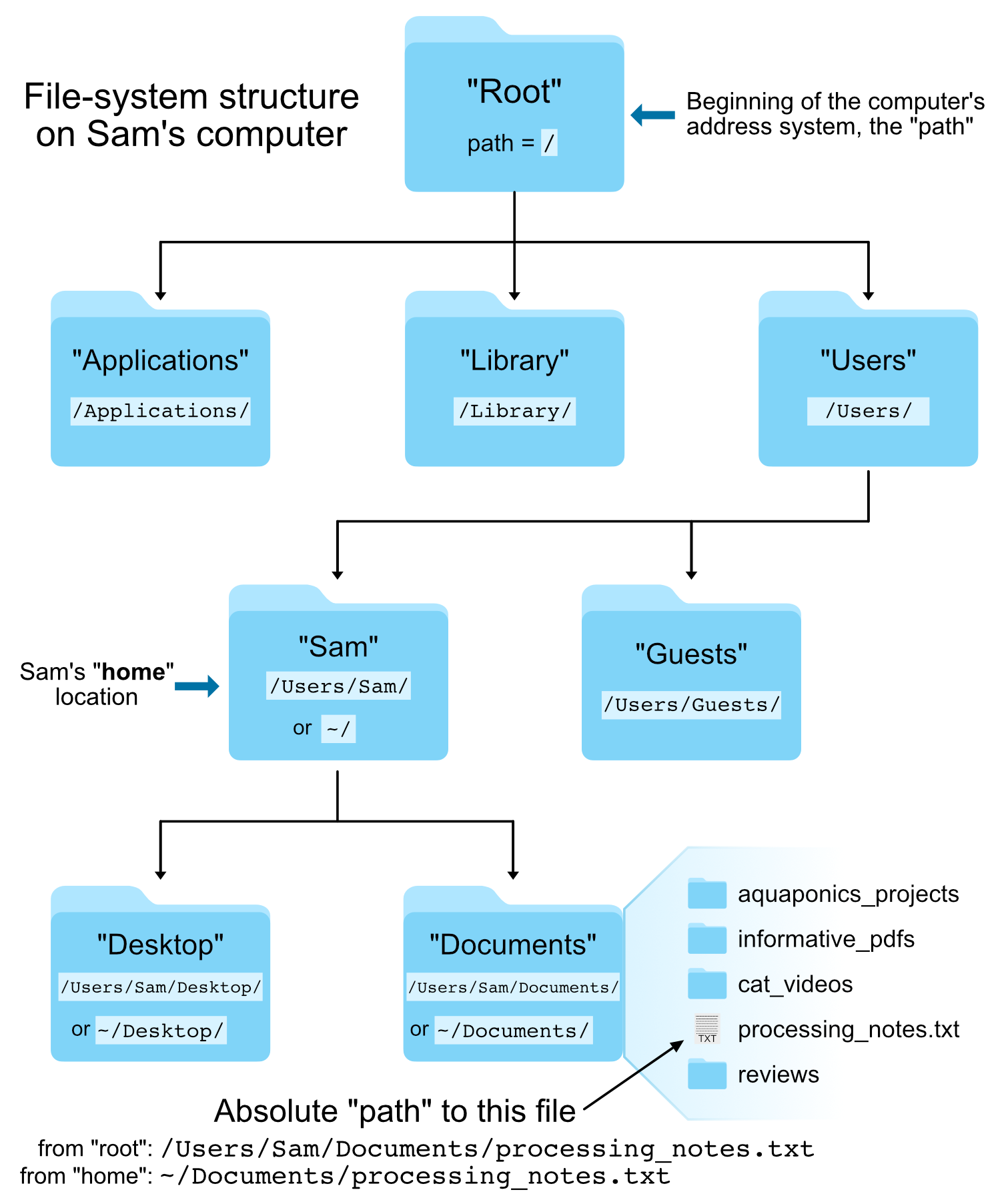
We tell the command line where files and directories are located by providing their address, their “path”. If we use the pwd command (for print working directory), we can find out what the path is for the directory (folder) we are sitting in:
pwd
Note that is providing the path starting from the special root location, because it begins with that leading /, which is the special character that denotes the start of the address system.
And we can use the ls command (for list) to see what directories and files are in the current directory we are sitting in:
ls
Absolute vs relative path
There are two ways to specify the path (address in the computer) of the file we want to find or do something to:
- An absolute path is an address that starts from one of those two special locations we mentioned above: either the “root” (specified with
/) or the “home” location (specified with~/). (Side note, because we also may see or hear the term, the “full path”, is the absolute path that starts from the “root”/.) - A relative path is an address that starts from wherever we are currently sitting.
These can sound a little more confusing at first than they are, so it’s best to just look at some examples.
Let’s start by looking again at the head command we ran above:
head example.txt
What we are actually doing here is using a relative path to specify where the “example.txt” file is located. The command line automatically looks in the current working directory if we don’t specify anything else about a file’s location. So this works specifically because there is a file called “example.txt” in the current directory we are sitting in where we are running the command.
We can also run the same command on the same file using an absolute path:
head ~/unix_intro/example.txt
There we are using the special “home” location, specified by the ~/ at the start, then going into the directory that holds the file, then naming the file.
The previous two commands both point to the same file. But the first way, head example.txt, will only work if we are entering it while “sitting” in the directory that holds that file, while the second way will work no matter “where” we happen to be in the computer.
Note: The address of a file, its “path”, includes the file name also, it doesn’t stop at the directory that holds it.
It is important to always think about where we are in the computer when working at the command line. One of the most common errors/easiest mistakes to make is trying to do something to a file that isn’t where we think it is.
Let’s run head on the “example.txt” file again, using a relative path by just providing the name of the file, and then let’s try it on another file, “notes.txt”:
head example.txt
head notes.txt
Here the head command works fine on “example.txt”, but we get an error message when we call it on “notes.txt” telling us no such file or directory.
If we run the ls command to list the contents of the current working directory, we can see the computer is absolutely right – spoiler alert: it usually is – and there is no file here named “notes.txt”.
ls
The ls command by default operates on the current working directory if we don’t specify any location, but we can tell it to list the contents of a different directory by providing it as a positional argument:
ls experiment
We can see the file we were looking for is located in this sub-directory called “experiment”. Here is how we can run head on “notes.txt” by specifying an accurate relative path to that file:
head experiment/notes.txt
If we had been using tab-completion, we would not have made that mistake!
BONUS ROUND: Tab-completion is our friend!
Tab-completion is a huge time-saver, but even more importantly it is a perpetual sanity-check that helps prevent mistakes.
If we are trying to specify a file that’s in our current working directory, we can begin typing its name and then press the tab key to complete it. If there is only one possible way to finish what we’ve started typing, it will complete it entirely for us. If there is more than one possible way to finish what we’ve started typing, it will complete as far as it can, and then hitting tab twice quickly will show all the possible options. If tab-complete does not do either of those things, then we are either confused about where we are, or we’re confused about where the file is that we’re trying to do something to – this is invaluable.
Quick Practice
Try out tab-complete! Runlsfirst to see what’s in our current working directory again. Then typehead eand then press thetabkey. This will auto-complete out as far as it can, which in this case is up to “ex”, because there are multiple possibilities still at that point. If we presstabtwice quickly, it will print out all of the possibilities for us. And if we enter “a” and presstabagain, it will finish completing “example.txt” as that is the only remaining possibility, and we can now pressreturn.
Moving around
We can also move into the directory containing the file we want to work with by using the cd command (change directory). This command takes a positional argument that is the path (address) of the directory we want to change into. This can be a relative path or an absolute path. Here we’ll use the relative path of the subdirectory, “experiment”, to change into it (use tab-completion!):
cd experiment/
pwd
ls
head notes.txt
Great. But now how do we get back “up” to the directory above us? One way would be to provide an absolute path, like cd ~/unix_intro, but there is also a handy shortcut. .. are special characters that act as a relative path specifying “up” one level – one directory – from wherever we currently are. So we can provide that as the positional argument to cd to get back to where we started:
cd ..
pwd
ls
Moving around the computer like this may feel a bit cumbersome at first, but after spending a little time with it and getting used to tab-completion you’ll soon find yourself slightly frustrated when you have to scroll through a bunch of files and click on something by eye in a GUI 🙂
Summary
While maybe not all that exciting, these things really are the foundation needed to start utilizing the command line – which then gives us the capability to use lots of tools that only work at a command line, manipulate large files rapidly, access and work with remote computers, and more! Next we’re going to look at some of the ways to work with files and directories.
Terms introduced:
| Term | What it is |
|---|---|
path |
the address system the computer uses to keep track of files and directories |
root |
where the address system of the computer starts, / |
home |
where the current user’s location starts, ~/ |
absolute path |
an address that starts from a specified location, i.e. root, or home |
relative path |
an address that starts from wherever we are |
tab-completion |
our best friend |
Commands introduced:
| Command | Function |
|---|---|
date |
prints out information about the current date and time |
head |
prints out the first lines of a file |
pwd |
prints out where we are in the computer (print working directory) |
ls |
lists contents of a directory (list) |
cd |
change directories |
Special characters introduced:
| Characters | Meaning |
|---|---|
/ |
the computer’s root location |
~/ |
the user’s home location |
../ |
specifies a directory one level “above” the current working directory |